パソコンを使っていると、ワードやノードパッドなどのエディタやそれ以外のアプリで、検索や置換をやったことある人は多いと思います。例えば、長い文章の中で、自分の指定した単語を一気に変えることができたりして、ほんとうに便利ですよね。
でも、たまに、特定の行の先頭に「・」を入れたいとか、郵便番号は「数字3桁-数字4桁」になっているかを確認したいとか、完全に文字が一致するのではなく、もう少しあいまいな、「こんな感じ」ということを表現したいことがあります。
パソコンでは、このようなことを「正規表現」といいます。何が「正規」なのかはそれこそあいまいですが、英語では、「Regular Expression」と言いますから、それを直訳したような表現ですね。正規表現にあまりなじみのない方も、「*」(ワイルドカード)という言葉は聞いたことがあるのではないでしょうか。トランプのジョーカーのように、何にでもマッチすることを意味して、「か*」であれば、「かに」でも「かき」でも当てはまるといった感じです。
「*」は正規表現の中でも代表的なものですが、それ以外にもいろいろな表現があり、それらをある程度マスターすると、パソコンを使う上で様々な作業で使えます。
あなたがもし、Webデザイナーやプログラマーの方であれば、入力チェックや、データのクレンジングなど、業務にも使える場面が多いことでしょう。
私も様々な場面でお世話になっている「正規表現」ですが、はじめに体系的に理解していないと、毎回Webで検索したものをコピペで使い、その意味を理解していない感じでした。なので、これから数回にわたって正規表現をしっかり理解し、自由に使いこなせるようにまとめたいと思います。
正規表現を使ってみるには
今どきのテキストエディタの多くは、検索や置換のオプションに「正規表現」が指定できるようになっています。私のよく使うのは、秀丸やサクラエディタ、EmEditorなどですが、いずれもそのようなオプションを持っています。下記はサクラエディタの置換のオプションですが、「正規表現」というのがありますね。ここにチェックが入っていると、通常の完全に一致する文字を検索してきて、置換ではなく、正規表現を使った検索に変更することができます。
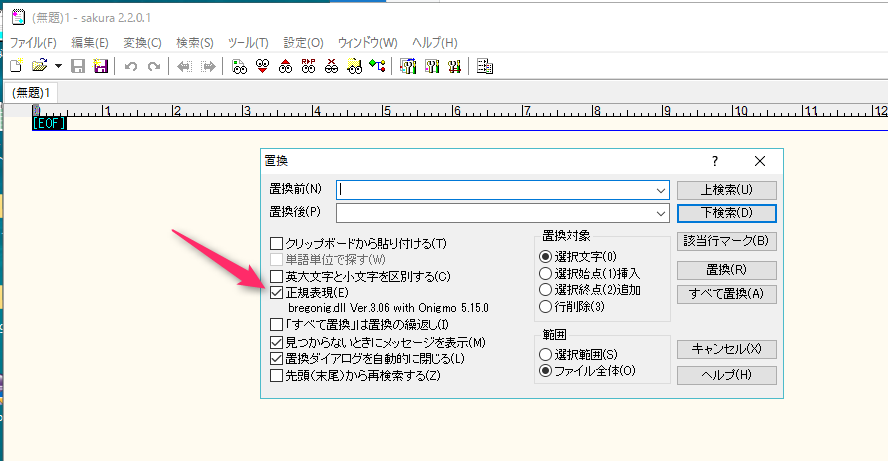
お使いのテキストエディタにこのようなオプションがある場合は、オンにすると、いろいろ正規表現を試すことができますので、是非、試してみてください。慣れれば慣れるほど、便利さを実感できると思います。
基本的なメタキャラクタ
正規表現では、「メタキャラクタ」という特別な文字を使います。上で出てきた「*」のような文字です。それ以外にもいくつかありますが、初めにきちんと押さえておけば、『^[a-zA-Z0]』こんなのを見た場合でもなんとなく理解できるようになります。
はじめに押さえておきたいのは、『^』です。山形とも呼ばれることがありますが、使いどころによって2つの意味があります。一つは、「行頭」、もう一つは「否定」の意味です。
行頭・・・単独で使われた場合

『^』が[]と組み合わされずに単独で使われると「行頭」の意味になります。『^』だけ使うとすべての行がマッチしますが、例のように『^T』と指定すると行頭にTのあることろ(図の黄色いところ)がマッチすることになります。
否定・・・[ ]の中で文字の前に使われた場合

ややこしいことに、『^』にはもう一つの意味があります。[](ブラケット)の中で使われると、「^に続けて指定した以外の文字」という否定の意味になるのです。下でも述べますが、[]の中で文字のリストを指定すると、「指定された文字リストのうちのどれか」という意味になりますが、そこに『^』を指定することで、「指定された文字リスト以外の文字のうちのどれか」という意味になります。例でいうと、[a-z]はa~zの英文字のいずれかという意味なので、[^a-z]は、a~zの英文字以外の文字のいずれかという意味になります。そのため、英文字以外のところがすべてヒットして黄色くなっているわけです。すこしややこしいですが、『^』は頻出するため、これを覚えておくと、混乱しないです。
前述の『^』と対で覚えておくと便利なのが『$』です。ドル記号ですが、意味は「行末」となります。
行末を表す

『$』は概念的な行の末尾を表しますので、そのままだと、すべての行の末尾が当てはまります。そのため、例のようにほかの文字と組み合わせて使うと、特定の文字で終わる行を特定することができます。『^』と『$』を組み合わせると、特定の文字列をタグ(など)で囲むといったことも簡単にできるようになります。
『.』はピリオドで、任意の一文字を表します。この任意の文字の中には、英文字、数字、スペース、記号など全部入りますので、「なんでもいいけど、文字数が2文字」みたいなことを簡単に「..」で表現できます。例えば「..c」と表現すると「abc」や「ccc」はヒットしますが「ac」などはヒットしません。

例は、「…e」と指定したので、「任意の3文字の後にeが続く所」がヒットして黄色くなっています。スペースも任意の一文字に数えられることに注意しましょう。

『*』は正規表現では、単独では用いられません。「直前に指定された文字の0回以上の繰り返し」を表現します。よくWindowsとかで使用するワイルドカードとしての意味ではないので、混乱してしまいますが、正規表現で使用する場合には、直前の文字とセットで初めて意味があると覚えておきましょう。例えば、「a*」は、直前の文字「a」の0回以上の繰り返しを表すので、「」、「a」、「aa」、「aaaaaaaa」のどれにもヒットします。注意したいのは、aがなくてもヒットするということですね。なので、「Apple*」と指定すると、最後の「e」の0回以上の繰り返しなので、「Appl」「Apple」「Appleeeee」等にヒットします。
直前の文字があってもなくてもいいが、ある場合は何個続いてもよい

例では「p*l」を指定したので、pが0回以上続いた後にl(エル)が続く所がヒットして黄色くなっています。

『?』は疑問文でもよく目にすることが多いので、混乱しやすいメタキャラクタの一つです。このクエスチョンマークも正規表現では、単独では用いられません。「直前に指定された文字の0回または1回の繰り返し」を表現します。例えば、「a*」は、直前の文字「a」がの0回または1回の繰り返しを表すので、「a」または「aa」のいずれかにヒットします。『*』との違いを分かりやすくするために「Apple?」とすると、「Appl」「Apple」だけにヒットします。最後の文字があいまいなんだけど。。というようなシチュエーションで使える、結構重宝する表現です。要は、「最後の文字はあってもなくてもいいだけど」というようなあいまいな指定ができます。
直前の文字の0回または1回の繰り返しを表す

例では「apple?」を指定したので、appleの最後のeが0回または1回続くところがヒットして黄色くなっています。

『+』は「直前に指定された文字の1回以上の繰り返し」を表現します。つまり、「直前の文字を必ず含むこと!」ということが表現できるわけです。例えば「Apple+」とすると、「Apple」や「Appleeee」にヒットしますが「Appl」にはヒットしません。最後が必ずeで終わるというときの表現です。
直前の文字の1回以上の繰り返しを表す

例では「apple+」を指定したので、appleの最後がeで終わる単語がヒットします。「allp」はヒットしないので黄色くなっていませんね。

『-』はこの前後に指定された範囲の文字すべてを表します。例えば数字1文字を表す正規表現は[0123456789]とも書けますが[0-9]と書いた方が簡潔ですよね。同様に[a-z]は任意の英数字一文字を表現します。すこし注意したいのは、「範囲」を表すのは前後に文字があるときだけで、[-0]や[09-]、-[]、[]- などは通常の「マイナス」という文字を表し、正規表現ではないということです。[ ]の中で文字に挟まれているときだけ、正規表現のメタキャラクタとして認識されると覚えておきましょう。
前後の文字の範囲を表す

例では「apple[0-9]」を指定したので、appleの最後が数字で終わる単語がヒットします。「allpe」は数字なしなのでヒットせず、黄色くなっていませんね。

『[』と『]』はブラケットといい、組み合わせて使います。この[ ]の中に文字を羅列すると、その文字のいずれか1つを表現できます。この中には任意の文字を何個でも書けますが、意味するのは、このうちの1字です。つまり、『[abcd]』と書いてあっても、ヒットするのは「a」か「b」か「c」か「d」かです。『[ab]c』と書くと、「ac」または「bc」にヒットするということですね。『[ ]』を理解すると、正規表現の幅がずっと広がります。前述した『-』は『[]』内で範囲を表すのでしたね。つまり、『[a-zA-Z0-9]』と書けば、大文字と小文字の英文字または数字全部のうちの一文字を表現していることになります。注意したいのは、最初に出てきた『^』は、『[]』の中で使われるときだけ、「否定」の意味になるということでした。それ以外のメタキャラクタは、ほとんど、ブラケットの中では単なる文字として認識されます。これをうまく使うと、『[]』で囲ってしまえば、特殊な文字も文字として指定できるということになります。つまり、『[!#$%&’_`/=~]』こんなのが出てきたとしても、「この文字のうちのどれか一文字」を表現しているにすぎません。
前後の文字の範囲を表す

例では「p[ep]」を指定したので、peまたはppにヒットしています。
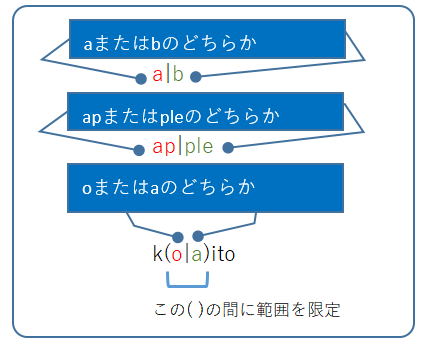
『|』は前後に指定された文字列のどちらかにマッチします。例えば『a|b』は「a」または「b」のどちらか一方だということです。注意したいのは、前後の文字が1文字でも複数文字でもそれ全体がヒットするということです。つまり、『ap|ple』は、「ap」または「ple」にヒットするということです。では、一文字だけを指定したい場合はどうすればいいのでしょうか。正規表現では、効果の範囲をしてするのに、『()』を使います。例えば、『k(o|a)ito』とすると、「koito」または「kaito」にマッチすることになります。
前後の文字のどれか一方を表す

例では「Apple|pen」を指定したのでappleまたはpenにヒットしています。
『(』と『)』はこれらに囲まれた正規表現を一つのまとまりとして定義する場合に使われます。よく使われるのは、上で出てきた『|』の前後に指定された文字列の範囲を指定する場合や、後方参照とよばれるプログラムの中です。
グループ化

例では「A(pple|)pen」を指定したので、「pple」または「空文字」のいずれかとなるので、ApplepenまたはApenにヒットしています。
『\b』は単語の境界を表します。例えば、「This is a pen.」という文章があった場合、単純に「is」を指定すると、「This」と「is」の両方の「is」にマッチしてしまいますね。後者の「is」だけを指定したい場合には、どうすればいいでしょうか。そんな時に使えるのが『\b』です。単語と単語の間の空白を意味しますので、「\bis」と指定したら、後者の「is」だけにマッチすることになります。
単語境界

解説したのと同様、Thisのisにはヒットせず、後ろのisが黄色くなっているのが分かります

上で『+』が出てきたとき、「一回以上の繰り返し」ということでした。1回以上ということですので、100回でも1000回でもマッチするのですが、さすがにそこまでの一致は少ない場合が多いでしょう。『{min,max}』を使うとその繰り返しの回数を指定できます。例えば、『a{3,5}』と指定すると、aの3回から5回までの繰り返しにマッチします。なお、minとmaxは必ずしも両方指定する必要はありません。また、一方だけ指定した時、カンマを付けるかつけないかで意味が変わってきます。例を挙げると、『a{2}』は「aの2回の繰り返し」にマッチします。『a{2,}』は「aの2回以上の繰り返し」という意味になります。『a{,2}』だと、0回以上、2回までの繰り返しになるというわけです。
繰返し範囲

例では『ap{2,3}le』と指定したので、pが2または3つある単語にヒットしてるのが分かりますね。
基本メタキャラクタまとめ
| メタキャラクタ | 読み方 | 意味 |
|---|---|---|
| ^ | キャレット,山形 | 「行頭」 もしくは 「否定」 |
| $ | ドルマーク | 行末 |
| . | ピリオド | 任意の一文字 |
| * | アスタリスク | 直前の文字の0回以上の繰り返し |
| ? | クエスチョンマーク | 直前の文字の0回または1回の繰り返し |
| + | プラス | 直前の文字の1回以上の繰り返し |
| – | マイナス | 前後の文字の範囲 |
| [] | ブラケット | [ ]の間に記述された文字のうちどれか一文字 |
| | | 縦一文字 | |の前後に記述された文字のうちどれか一方 |
| () | カッコ | ()の間の正規表現をひとまとまりとしてとらえる(グループ化) |
| \b | 円マークとb | 単語境界 |
| {min,max} | 繰り返し数の範囲 |